Hinweise zu SPSS
Dies ist ein Teil der Begleitseite zu Gries, Stefan Th. 2008. Statistik für Sprachwissenschaftler. Vandenhoeck und Ruprecht. Auf dieser Webseite werden ein paar Hinweise dazu gegeben, wie viele der im Buch diskutierten Verfahren mit SPSS gerechnet werden können. Allerdings ist zuvor eine Vorabbemerkung erforderlich: Ich persönlich finde, dass der Leser unbedingt nicht SPSS verwenden sollte:
- R ist inzwischen die führende Anwendung und Programmierumgebung für Statistik oder zumindest auf dem allerbesten Wege dahin.
- Viele Dinge sind mit der Benutzeroberfläche SPSS gar nicht möglich: wenn Sie eine Analyse machen und sie nach drei Monaten wiederholen wollen, dann müssen Sie genau wissen, welche Optionen gewählt wurden etc. und sich dann durchklicken – in R laden Sie einfach das Skript und alles läuft von alleine.
- Aus diesem Grund ist auch der Austausch kompletter statistischer Analysen viel einfacher: Sie verschicken einfach das Skript und alles wird repliziert, und das sogar über verschiedene Computersysteme:
- SPSS ist nicht in gleicher Form für alle Betriebssysteme verfügbar – R schon.
- Ich habe schon mehrere R-Programme geschrieben, die ich Linguisten überall zur Verfügung stellen kann, ohne dass diese eine kommerzielle Anwendung kaufen müssen – mit der SPSS Benutzeroberfläche wäre das sehr viel umständlicher.
- SPSS kann bestimmte Dateigrössen gar nicht bearbeiten: Als Korpuslinguist hatte ich öfter schon Datensätze, die SPSS nicht mal laden konnte.
- R ist eine Programmierumgebung, die neben Statistik auch noch ganz anderen Dinge zur Verfügung stellt: in meiner Einführung in die Korpuslinguistik beispielsweise bespreche ich, wie man nahezu alles, was ein Korpuslinguist je machen wollen würde, auch mit R machen kann; R kann dazu in HTML, PDF oder LaTeX ausgeben, mit SQL, Perl, Python interfacen. D.h., der Anwender muss nur eine Anwendung lernen, und nicht SPSS für Statistik, X für Konkordanzen, Y für fortgeschrittene Grafiken, ... Das bedeutet auch, dass R flexibler mit unterschiedlichen Arten umgehen kann, in denen Daten vorliegen.
- Da R open source software ist, gibt es eine lebhafte community, die R ständig weiter entwickelt und bugfixes innerhalb kürzester Zeit und kostenfrei zur Verfügung stellt.
- SPSS ist für Dozenten und Studenten in Deutschland nicht allzu teuer, aber das heisst nicht, dass es für Unis günstig ist, und immer mehr Institutionen verwenden R, weil es nicht einzusehen ist, für ein Programm wie SPSS, das viel weniger kann als R, auch noch jährlich (!) Lizenzgebühren zu bezahlen – selbst Dozenten und Studenten können SPSS dann manchmal nur am Campus benutzen und nur im oft eingeschränkten Rahmen der verfügbaren Lizenz (oft sind nicht alle Module verfügbar oder die Studentenversion erlaubt nur bestimmte Datensatzgrössen) – mit R hat man immer alles, was es gibt.
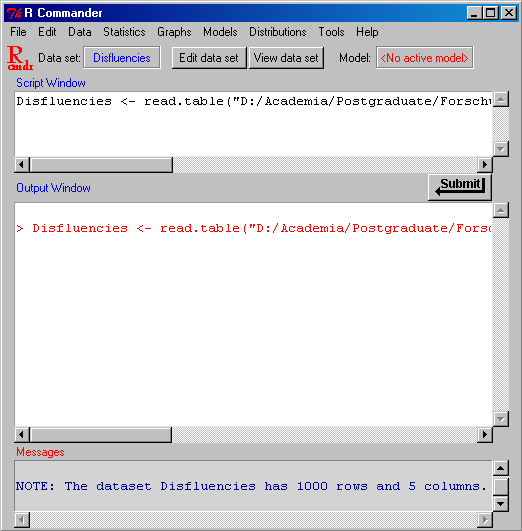
Also, verwenden Sie lieber R, so wie es im Buch diskutiert wird, oder den R commander (indem Sie die library (Rcmdr) und die dazugehoerigen anderen Pakete installieren und dann library(Rcmdr)¶ in R eingeben). Das hat den Vorteil, dass Sie weiterhin viele Vorteile von R geniessen, aber auch ein point-and-click interface benutzen können und dabei sogar noch R Syntax kennenlernen können: wann immer Sie etwas im R commander tun, bekommen Sie die R-Syntax angezeigt, die für Ihre Anwendung ausgeführt wurde:
R commander": Das Hauptfenster
|
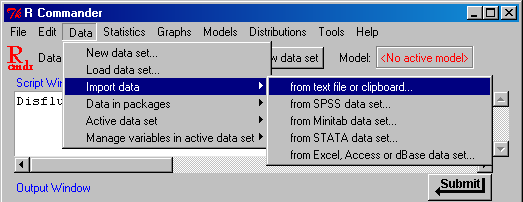
R commander: Importieren von Datendateien
|
Nun – trotz allem – zu SPSS ...
Laden und speichern einer Datei
Um die typische Art von Datendatei in SPSS zu laden, ist es oft am einfachsten, in der Menüleiste die Funktion "File: Read Text Data ..." zu verwenden. In dem dann folgenden Menü wählen Sie die entsprechende Textdatei und starten damit einen Text Import Wizard. Im ersten Schritt können Sie wählen, ob Sie ein vordefiniertes Format zum Laden verwenden wollen; hier antworten Sie wahrscheinlich "No". Im zweiten Schritt spezifizieren Sie, wie die Daten aufgebaut sind. Fast immer werden die Spalten durch ein bestimmtes Zeichen – einen Tabstop – begrenzt und haben Sie die Spaltennamen in der ersten Zeile. Im dritten Schritt müssen Sie üblicherweise nichts tun, wenn Sie einfach die ganze Datei laden wollen. Im vierten Schritt definieren Sie das Spaltentrennzeichen und das Zeichen, dass Text definiert. Im fünften Schritt können Sie für jede einzelne Spalte definieren, was für Daten sie enthält. Üblicherweise werden Sie die Formate "Numeric" und "String" verwenden wollen. Im letzten Schritt können Sie das definierte Format speichern oder, wahrscheinlich meistens, einfach nur die Datei laden. Um eine Datei zu speichern, wählen Sie in der Menüleiste "File: Save" oder "File: Save As ...".
Grundsätzliche Anmerkungen
Fast alle Verfahren funktionieren auf die gleiche Art. Sie wählen über die Menüleiste "Analyze:" und wählen das gewünschte Verfahren, was dann normalerweise ein Fenster öffnet, in dem Sie die beteiligten Variablen und allerlei Optionen auswählen können. Hier ein Beispiel für ein solches Fenster:
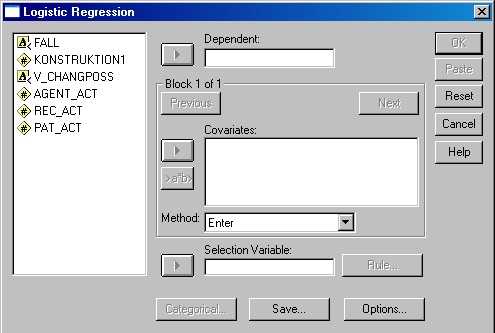
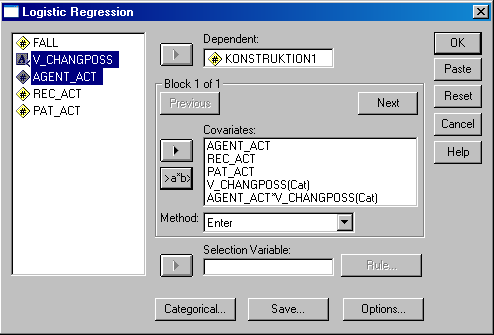
Links sehen Sie die im Datensatz enthaltenen Variablen. Um eine Variable wie z.B. KONSTRUKTION1 als abhängige Variablen in einer logistischen Regression zu definieren, klicken Sie links auf den Variablennamen und dann auf die Taste mit dem seitwärts zeigenden Dreieck links neben dem Feld mit dem Namen "Dependent". Um Variablen als unabhängige Variablen (hier als "Covariates" bezeichnet") zu definieren, klicken Sie links auf die Variablennamen und dann auf die Taste mit dem seitwärts zeigenden Dreieck links neben dem Feld mit dem Namen "Covariates" etc. Um dann Einstellungen für Kategorialvariablen vorzunehmen, klicken Sie dann unten auf die Taste "Categorical" etc. Weitere methodenspezifische Einstellungen können dann über die Tasten "Options" oder vergleichbare Tasten in anderen Verfahren definiert werden. In den folgenden Zeilen wird gezeigt, wo in SPSSs Menüstruktur Sie die meisten im Buch diskutierten Verfahren finden, wo Sie dann die Variablen etc. wie oben definieren können.
Kapitel 3: Deskriptive Statistik
- Abschnitt 3.1.1: Häufigkeiten und Häufigkeitstabellen: "Analyze: Descriptive Statistics: Frequencies"
- Abschnitt 3.1.1.1: Punkt-/Streu- und Liniendiagramme: "Graphs: Scatter ..." oder "Graphs: Line ... (für Liniendiagramme dann "Simple" und "Summaries for groups of cases" oder "Summaries for separate variables" auswählen und die Variablen definieren; mit dem Button "Change Summary" können Sie die zu plottende Funktion auswählen)
- Abschnitt 3.1.1.2: Kreisdiagramme: "Graphs: Pie ..."
- Abschnitt 3.1.1.3: Balkendiagramm: "Graphs: Bar ..."
- Abschnitt 3.1.1.4: Pareto-charts: "Graphs: Pareto ..."
- Abschnitt 3.1.1.5: Histogramme: "Graphs: Histogram ..."
- Abschnitt 3.1.2: Masse der zentralen Tendenz: "Analyze: Descriptive Statistics: Descriptives" oder "Analyze: Descriptive Statistics: Explore"
- Abschnitt 3.1.3: Dispersion und Streuungsmasse und zusammenfassende Funktionen: "Analyze: Descriptive Statistics: Descriptives" oder "Analyze: Descriptive Statistics: Explore" sowie "Analyze: Descriptive Statistics: Frequencies" und "Graphs: Boxplot", dann "Summaries for separate variables" auswählen und die Variablen definieren
- Abschnitt 3.1.4: Standardisierung: "Analyze: Descriptive Statistics: Descriptives" und dann "Save standardized values as variables" auswählen, was (eine) neue Spalte(n) mit den standardisierten Werten erzeugt
- Abschnitt 3.1.5.1: Konfidenzintervalle arithmetischer Mittelwerte: "Analyze: Descriptive Statistics: Explore"
- Abschnitt 3.1.5.2: Konfidenzintervalle relativer Häufigkeiten: "Analyze: Descriptive Statistics: Explore", wie für Mittelwerte, aber die Variablenausprägung, für die das Konfidenzintervall gewünscht wird, muss mit '1' kodiert sein (und alle anderen mit '0')
- Abschnitt 3.2.1: Häufigkeiten und Kreuztabellen: "Analyze: Tables: Basic tables" oder "Analyze: Descriptive: Crosstabs"
- Abschnitt 3.2.1.1: Balkendiagramme und Mosaikplots: "Graphs: Bar ..", dann "Stacked" und "Summaries for groups of cases" auswählen, dann "Define" klicken und die Felder für "Category Axis" und "Define Stacks by" definieren
- Abschnitt 3.2.1.3: Liniendiagramme: "Graphs: Line", dann "Multiple" und "Summaries for groups of cases" auswählen und die Variablen definieren; mit dem Button "Change Summary" können Sie die zu plottende Funktion auswählen
- Abschnitt 3.2.2: Mittelwerte: "Analyze: Compare Means: Means"
- Abschnitt 3.2.2.1: Boxplots: "Graphs: Boxplot", dann "Summaries for groups of cases" auswählen und die Variablen definieren
- Abschnitt 3.2.2.2: Interaktionsgraphen: "Graphs: Line", dann "Multiple" und "Summaries for groups of cases" auswählen und die Variablen definieren; mit dem Button "Change Summary" können Sie die zu plottende Funktion auswählen
- Abschnitt 3.2.3: Korrelationskoeffizienten und lineare Regression: "Analyze: Correlate: Bivariate" oder "Analyze: Regression: Linear" (zum Hinzufügen einer Regressionsgeraden auf die Grafik doppelklicken und dann "Chart: Add Chart Element: Fit Line at Total")
Kapitel 4: Analytische Statistik
- Abschnitt 4.1.1.1: Eine abhängige Variable (verhältnisskaliert): "Analyze: Nonparametric Tests: 1-Sample K-S", dann "Test Distribution" auf "Normal" setzen
- Abschnitt 4.1.1.2: Eine abhängige Variable (nominal/kategorial): "Analyze: Nonparametric Tests: Chi-square ..."
- Abschnitt 4.1.2.1: Eine abhängige Variable (verhältnisskaliert) und eine unabhängige Variable (nominal) (unabhängige Stichproben): "Analyze: Nonparametric Tests: 2 Independent Samples"
- Abschnitt 4.1.2.2: Eine abhängige Variable (nominal/kategorial) und eine unabhängige Variable (nominal/kategorial) (unabhängige Stichproben): "Analyze: Descriptive: Crosstabs"
- Abschnitt 4.1.2.3: Eine abhängige Variable (nominal/kategorial) (abhängige Stichproben): "Analyze: Nonparametric Tests: 2 Related Samples"
- Abschnitt 4.2.2: Unterschiedstest für eine verhältnisskalierte abhängige Variable: "Analyze: Compare Means: One-Way ANOVA", dann unter "Options "Homogeneity of variance test" auswählen
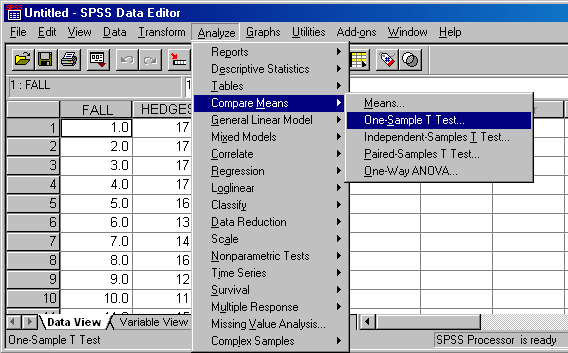
- Abschnitt 4.3.1.1: Eine abhängige Variable (verhältnisskaliert): Analyze: Compare Means: One-Sample T Test", dann im Feld "Test Value" den zu Nullhypothesenmittelwert eingeben:
SPSS: Einstichproben t-Test
|
R commander: Einstichproben t-Test

|
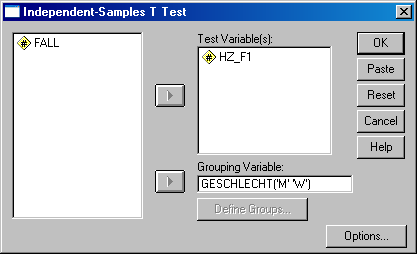
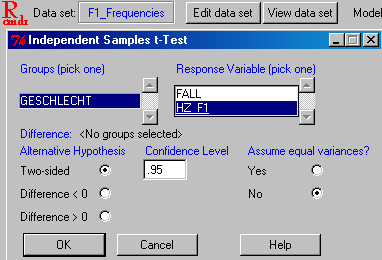
- Abschnitt 4.3.2.1: Eine abhängige Variable (verhältnisskaliert) und eine unabhängige Variable (nominal) (unabhängige Stichproben): Analyze: Compare Means: Independent-Samples T Test", dann die Variablen auswählen, "Define Groups" klicken und die beiden Variablenausprägungen eingeben:
SPSS: t-Test für unabhängige Stichproben
|
R commander: t-Test für unabhängige Stichproben
|
- Abschnitt 4.3.2.2: Eine abhängige Variable (verhältnisskaliert) und eine unabhängige Variable (nominal) (abhängige Stichproben): Analyze: Compare Means: Paired-Samples T Test", die beiden Stichproben müssen in unterschiedlichen Spalten vorliegen und daher erst anders angeordnet werden, bevor SPSS sie auswerten kann
- Abschnitt 4.3.2.3: Eine abhängige Variable (verhältnisskaliert): "Analyze: Nonparametric Tests: 2 Independent Samples", dann die Variablen auswählen, "Define Groups" klicken und die beiden Variablenausprägungen eingeben
- Abschnitt 4.3.2.4: Eine abhängige Variable (verhältnisskaliert): "Analyze: Nonparametric Tests: 2 Related Samples", die beiden Stichproben müssen in unterschiedlichen Spalten vorliegen und daher erst anders angeordnet werden, bevor SPSS sie auswerten kann
- Abschnitt 4.4: siehe oben zu Abschnitt 3.2.3
Kapitel 5: Ausgewählte mehrfaktorielle Verfahren
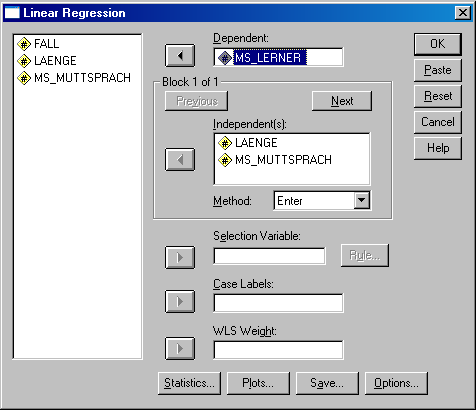
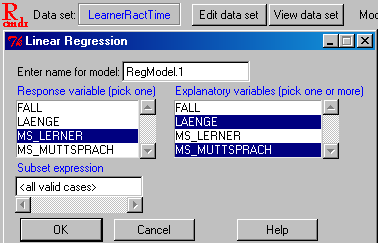
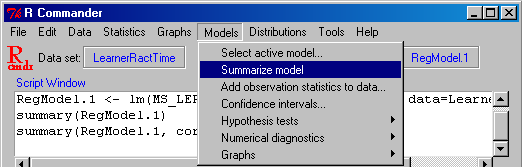
- Abschnitt 5.2: Multiple Regressionsanalyse: "Analyze: Regression: Linear":
SPSS: Lineare Regression
|
R commander: Lineare Regression
|
- Abschnitt 5.3.1: Einfaktorielle ANOVA: "Analyze: Compare Means: One-Way ANOVA" oder "Analyze: General Linear Model: Univariate", dann kann im Bereich "Model" das lineare Modell spezieller definiert werden und im Bereich "Options" Mittelwerte, Effektstärken und deskriptive Statistiken ausgewählt werden
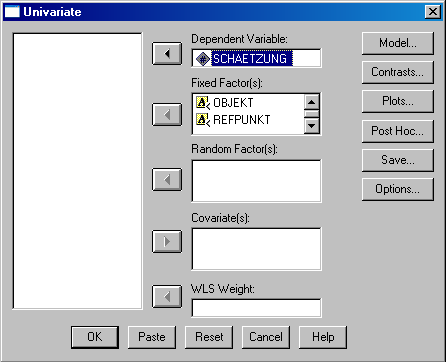
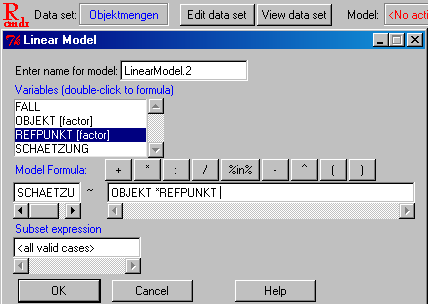
- Abschnitt 5.3.2: Zweifaktorielle ANOVA: "Analyze: General Linear Model: Univariate", dann kann im Bereich "Model" das lineare Modell spezieller definiert werden und im Bereich "Options" Mittelwerte, Effektstärken und deskriptive Statistiken ausgewählt werden:
SPSS: Multifaktorielle ANOVA
|
R commander: Multifaktorielle ANOVA
|
- Abschnitt 5.4: Binäre logistische Regression: "Analyze: Regression: Binary Logistic", Interaktionen zwischen 2+ Variablen werden mit der Taste ">a*b>" definiert und im Bereich "Options" kann ein Klassifikationsplot angefordert werden:
SPSS: Binäre logistische Regression
|
R commander: Binäre logistische Regression
|
- Abschnitt 5.5: Hierarchische agglomerative Clusteranalyse: "Analyze: Classify: Hierachical Cluster", dann auf "Method klicken, im Feld "Measure" ein Äehnlichkeitsmass auswählen und im Feld "Cluster Method" die Amalgamierungsregel auswählen